AWS Glue Triggers - Mình thử làm crawler được trigger chạy khi job
Share Everywhere







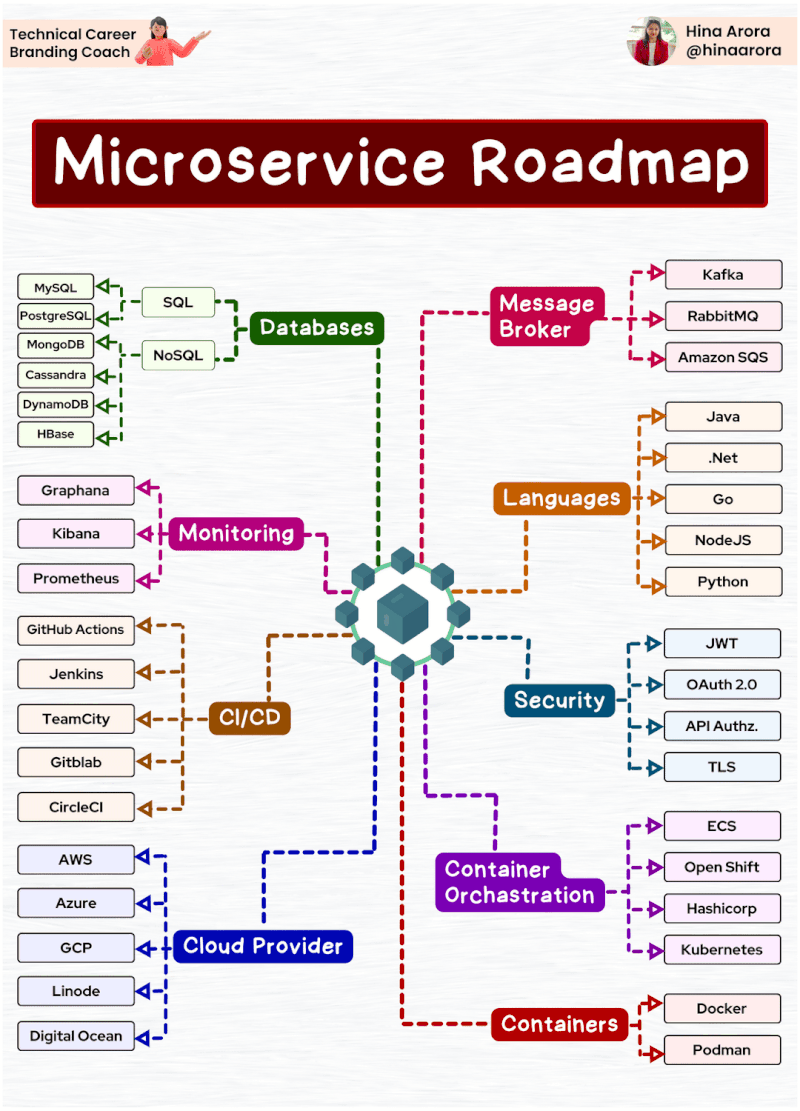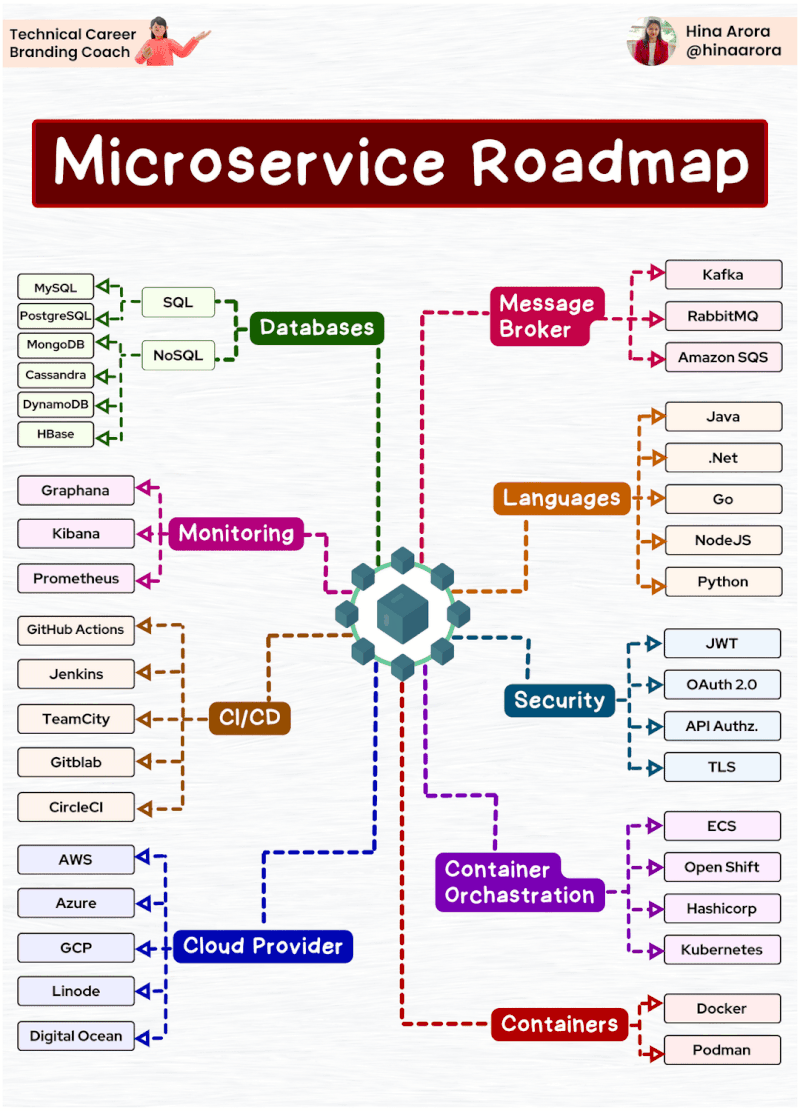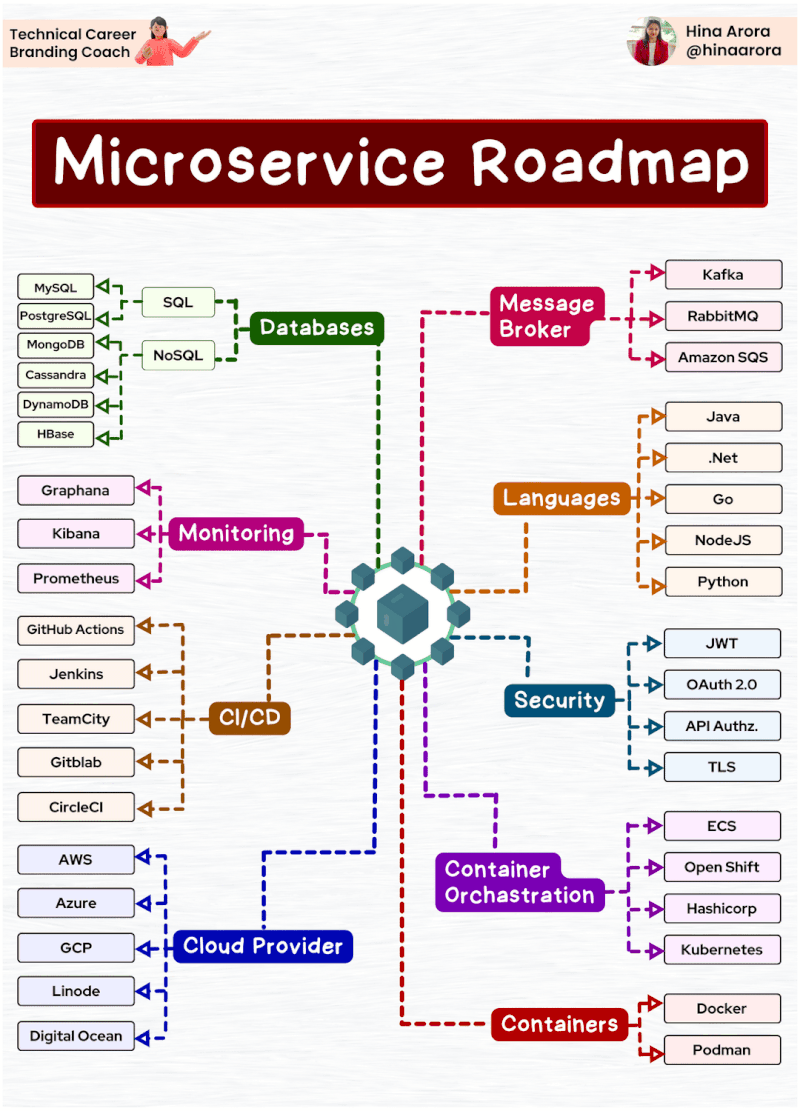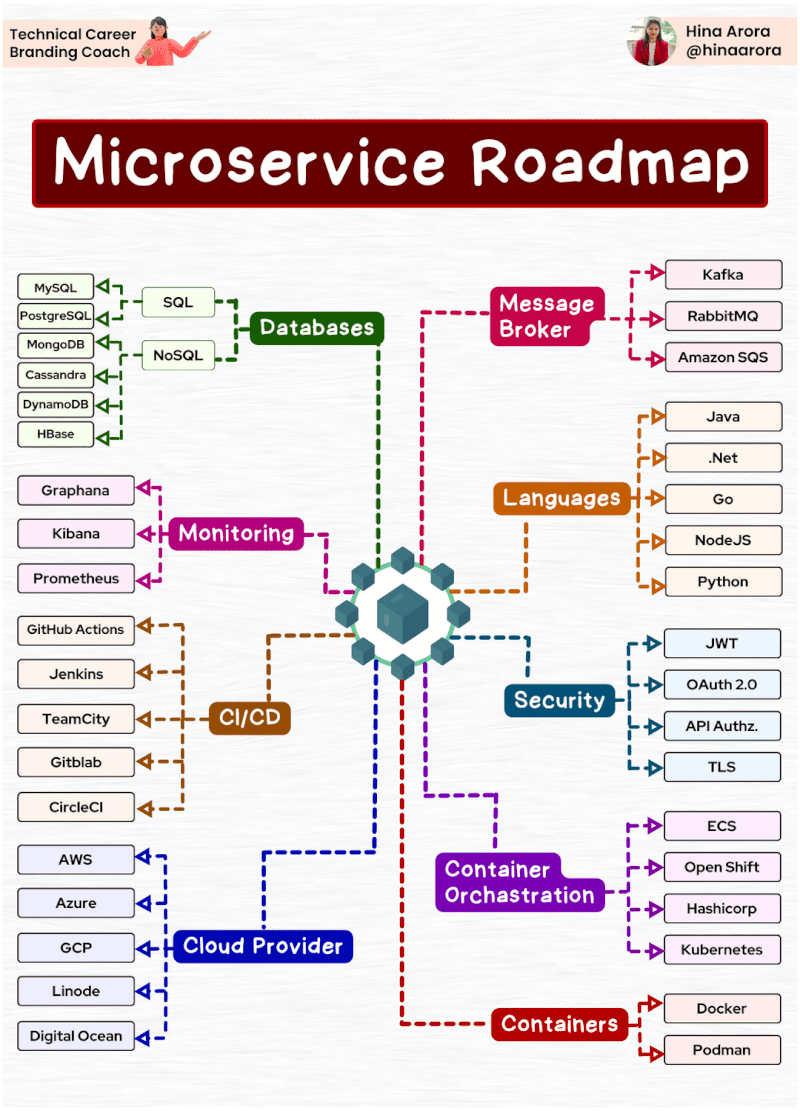
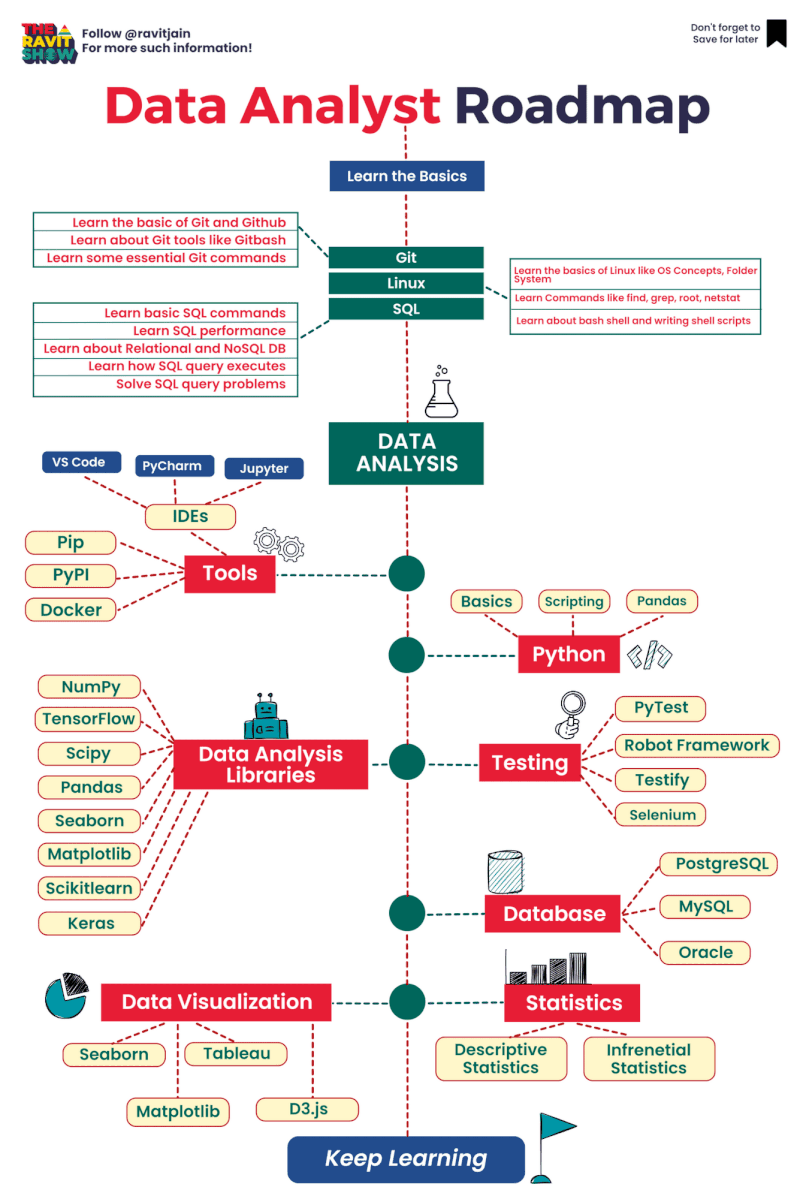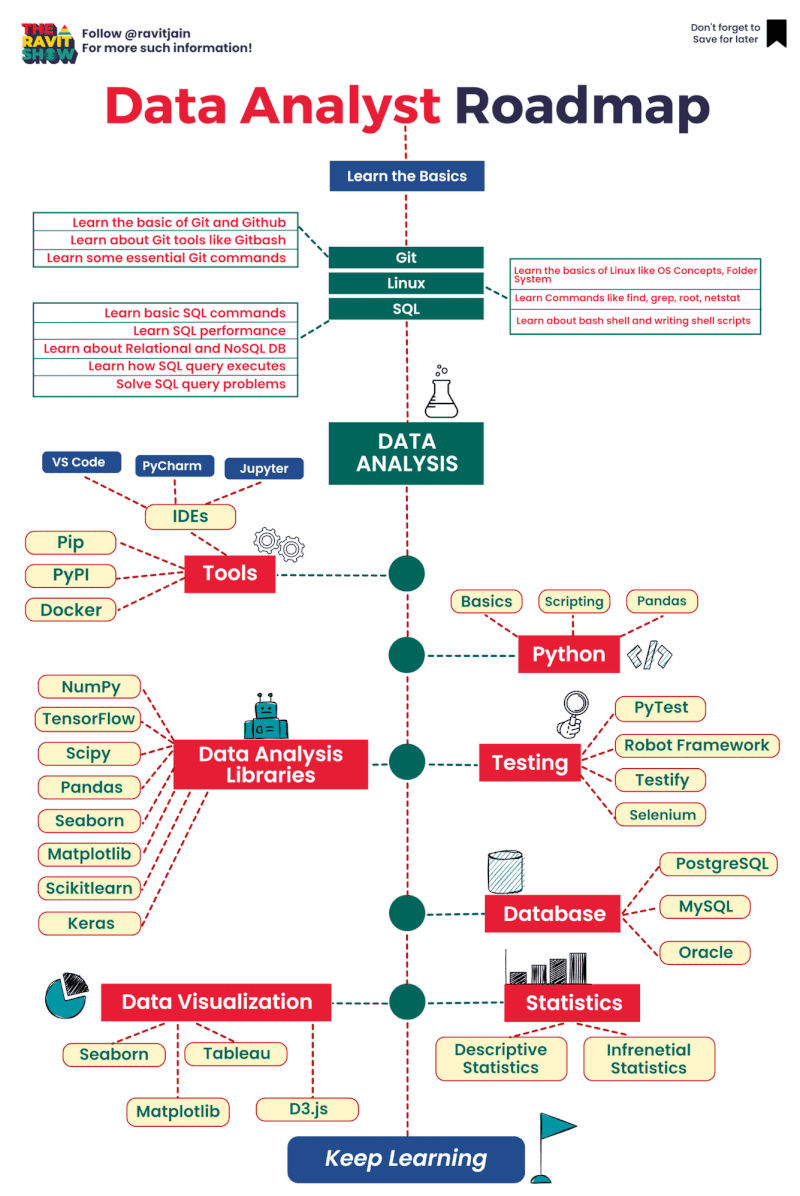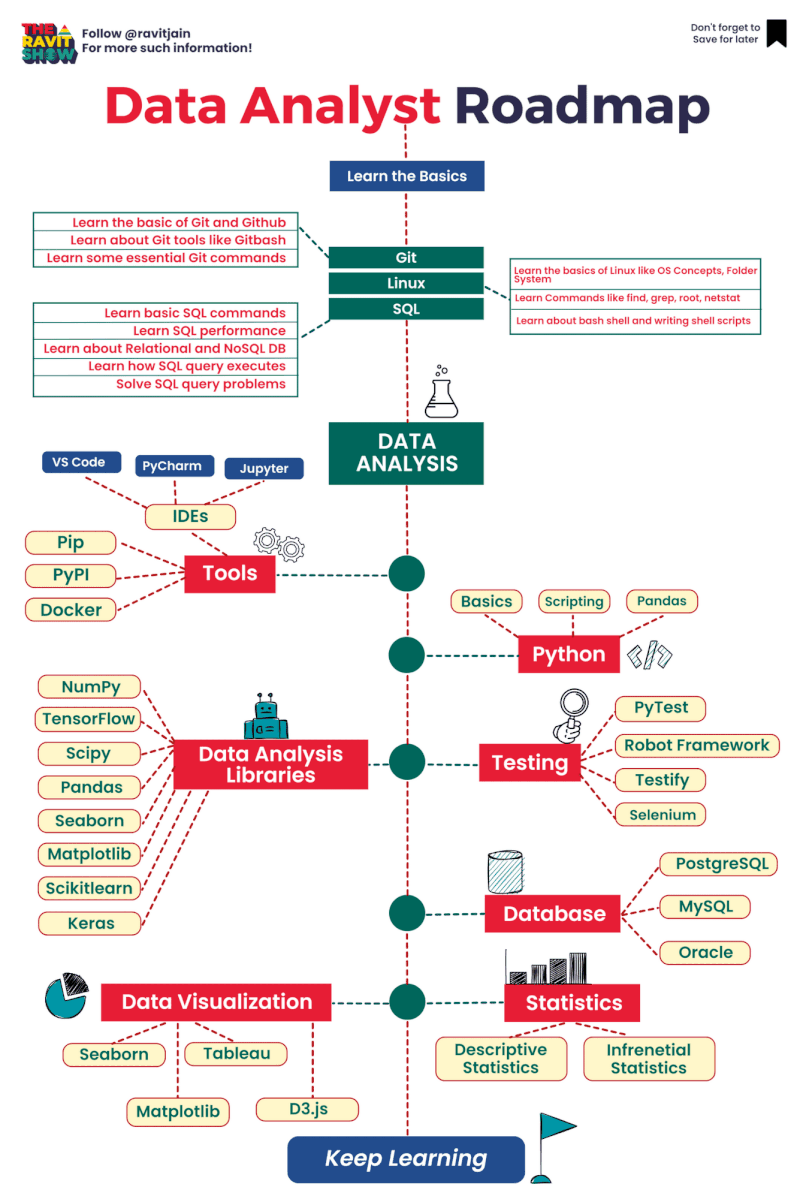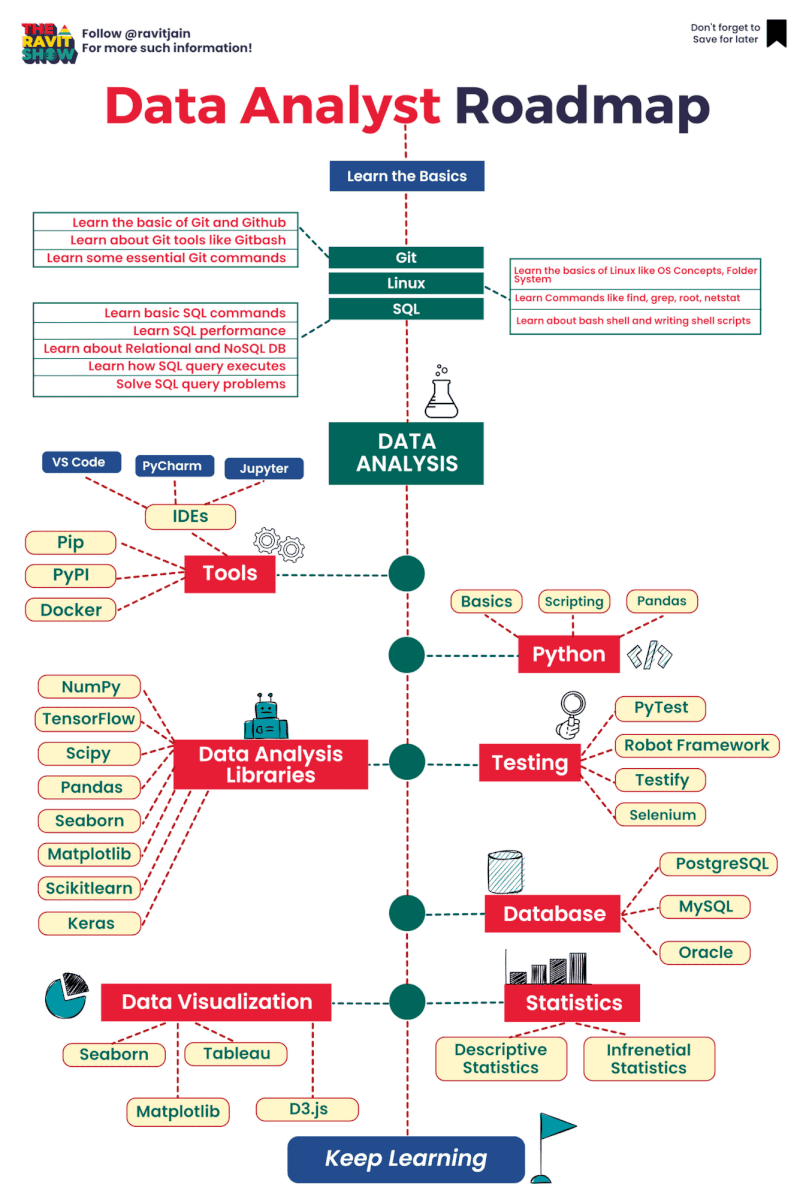
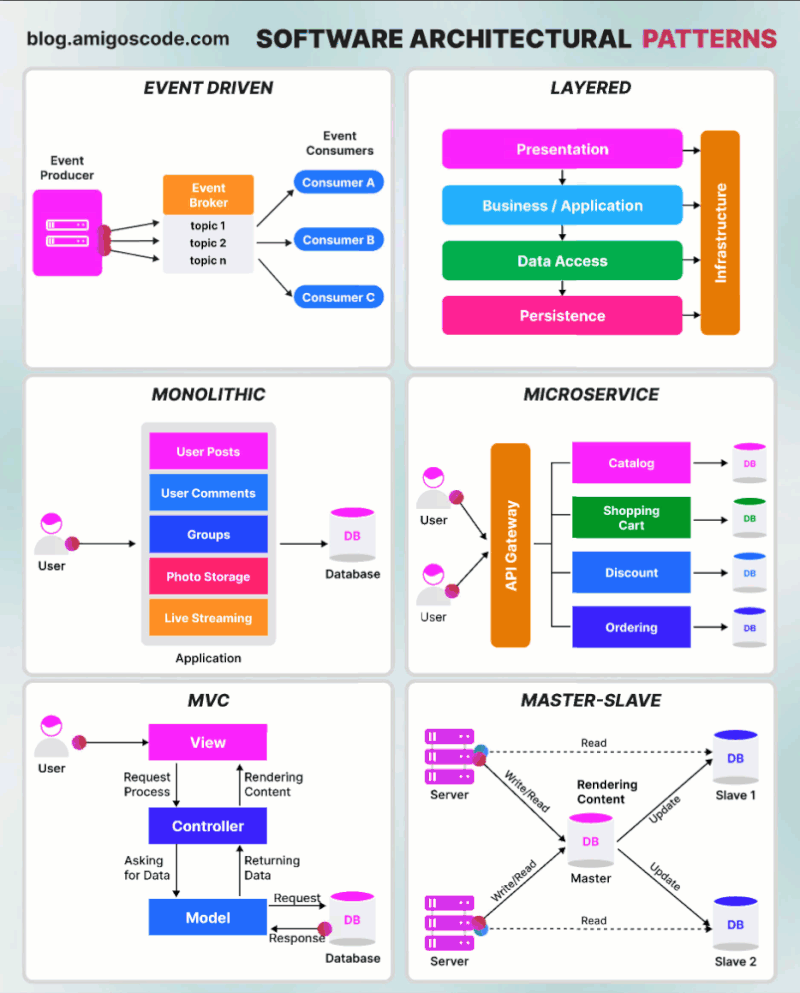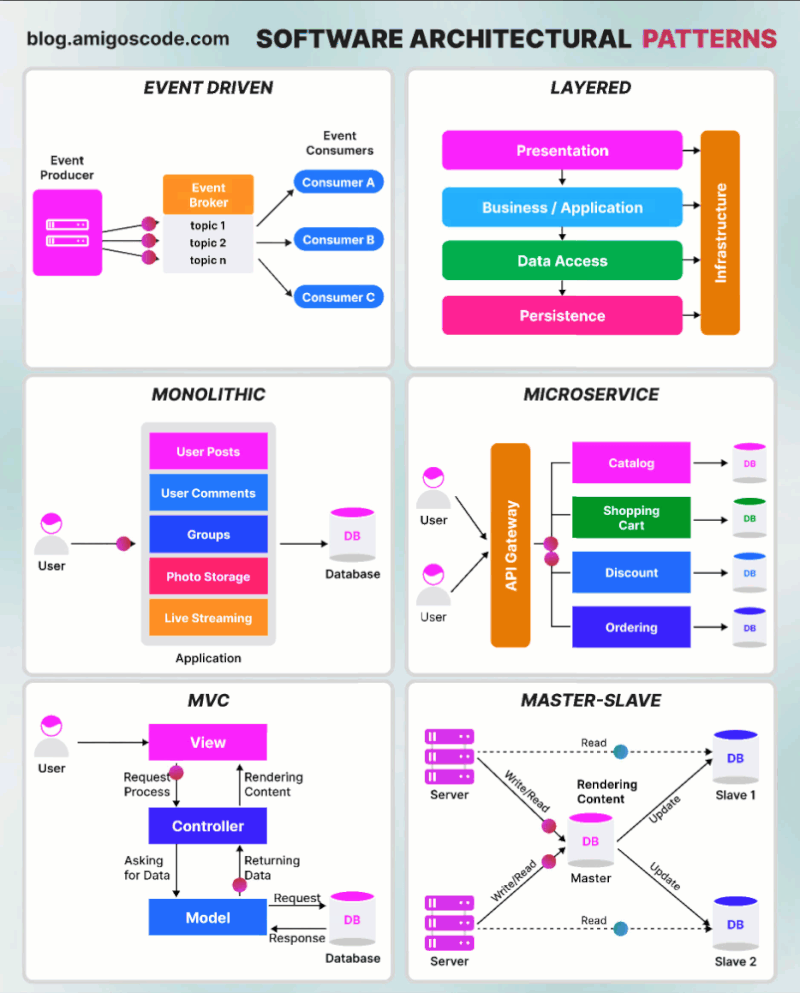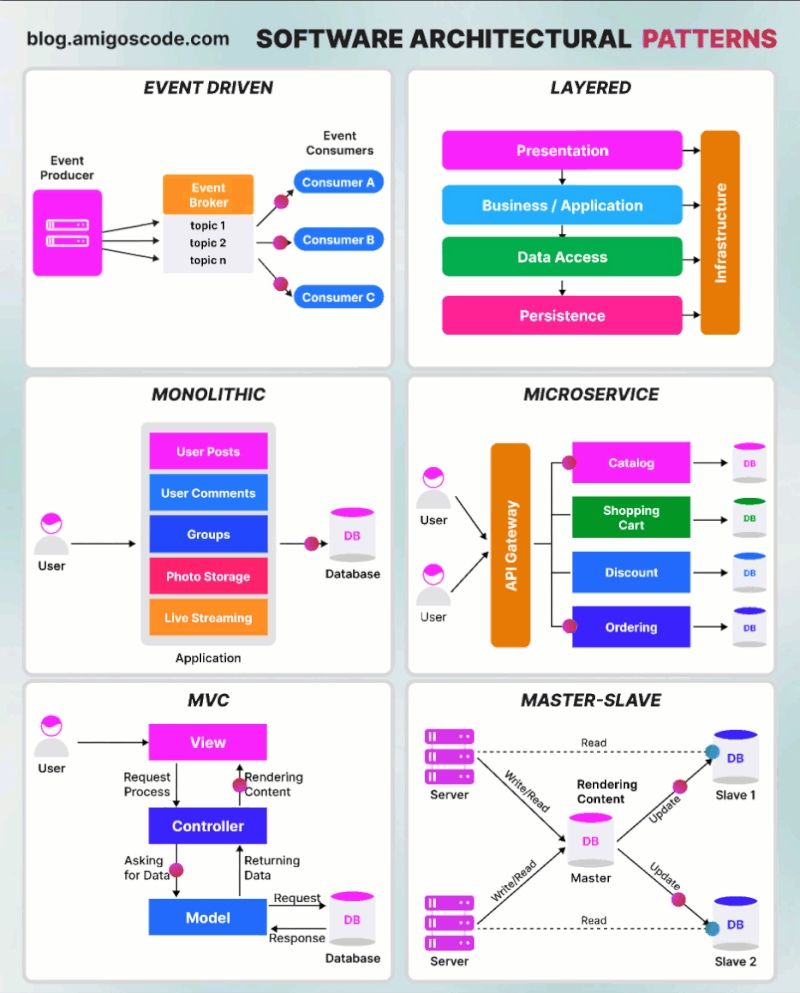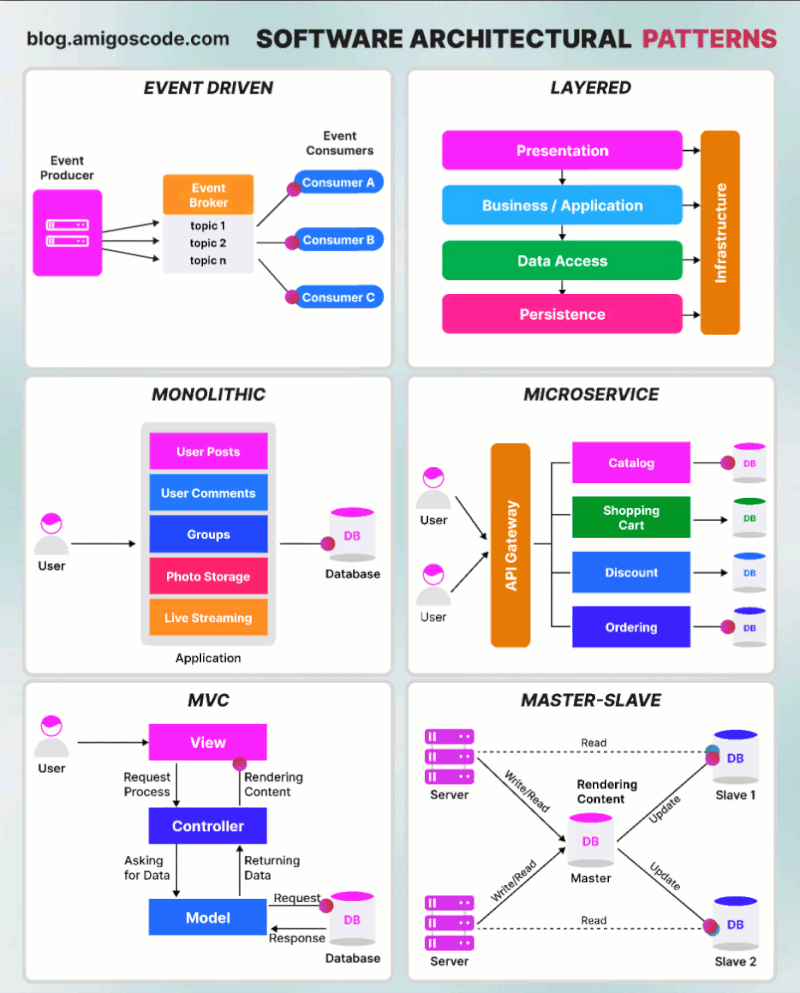
AWS Glue Triggers
Glue triggers are used to start one or more crawlers or extract, transform, and load (ETL) jobs. Using triggers, you can design a chain of dependent jobs and crawlers.
Currently, the AWS Glue console supports only jobs, not crawlers, when working with triggers, you can use the AWS CLI or AWS Glue API to configure triggers for both jobs and crawlers [1]. Looking into the create trigger CLI documentation [2] for creating a trigger for crawler, this does not have any examples. The intention of this article is to provide an example for creating trigger for crawler using AWS CLI, as triggers for ETL job can be created from the console.
Below is the example CLI command to create trigger for crawler
aws glue create-trigger --name testTrigger --type CONDITIONAL --predicate 'Logical=AND,Conditions=[{LogicalOperator=EQUALS,JobName=testJob,State=SUCCEEDED}]' --actions CrawlerName=testCrawler --start-on-creation
The above will create a trigger named ‘testTrigger’ which will start the crawler ‘testCrawler’ once the ‘testJob’ is succeeded. Note that the testJob needs to be started using a trigger only, if this is started manually then the testCrawler will not get fired by trigger. In Glue, dependent jobs or crawlers are only started if the job or crawler that completes was started by a trigger. All jobs or crawlers in a dependency chain must be descendants of scheduled or on-demand This behavior documented here [3].
The above trigger can also be created using python boto3 SDK.
import boto3
client = boto3.client('glue')response = client.create_trigger(
Name='testTrigger',
Type='CONDITIONAL',
Predicate={
'Logical': 'AND',
'Conditions': [
{
'LogicalOperator': 'EQUALS',
'JobName': 'testJob',
'State': 'SUCCEEDED'
},
]
},
Actions=[
{
'CrawlerName': 'testCrawler'
},
],
StartOnCreation=True,
)
Either of the above approach should assist to create a trigger for Glue crawler.
References
—
[1] https://docs.aws.amazon.com/glue/latest/dg/console-triggers.html
[2] https://docs.aws.amazon.com/cli/latest/reference/glue/create-trigger.html
[3] https://docs.aws.amazon.com/glue/latest/dg/about-triggers.html
Vấn đề
Có thể bạn sẽ gặp vấn đề Crawler không chạy dù job trả về đã success. Nếu vậy, hãy đọc tiếp nhé!
Nếu Job của bạn đã khởi động bằng tay (Job mà đã Job Succeeded nhưng thông tin [Triggered by] đang là blank như ảnh dưới đây)

thì Crawler không khởi chạy sau khi Job đã Job Succeeded.
Để trigger cho Crawler hoạt động thì Job cần được start bằng một Trigger khác [1]
Cách fix:
- Step 1: Tạo Glue Job, Crawler
- Step 2: Tạo Trigger cho Crawler. Sau khi run job bằng manual, xác nhận job đã succeeded nhưng Crawler không chạy giống như lỗi mà bạn đang gặp.
- Step 3: Tạo Trigger cho Job. Sau khi dùng trigger để start Job, Crawler đã chạy thành công
Tài liệu tham khảo:
[1] https://docs.aws.amazon.com/glue/latest/dg/about-triggers.html
Jobs or crawlers that run as a result of other jobs or crawlers completing are referred to as dependent. Dependent jobs or crawlers are only started if the job or crawler that completes was started by a trigger. All jobs or crawlers in a dependency chain must be descendants of a single scheduled or on-demand trigger.