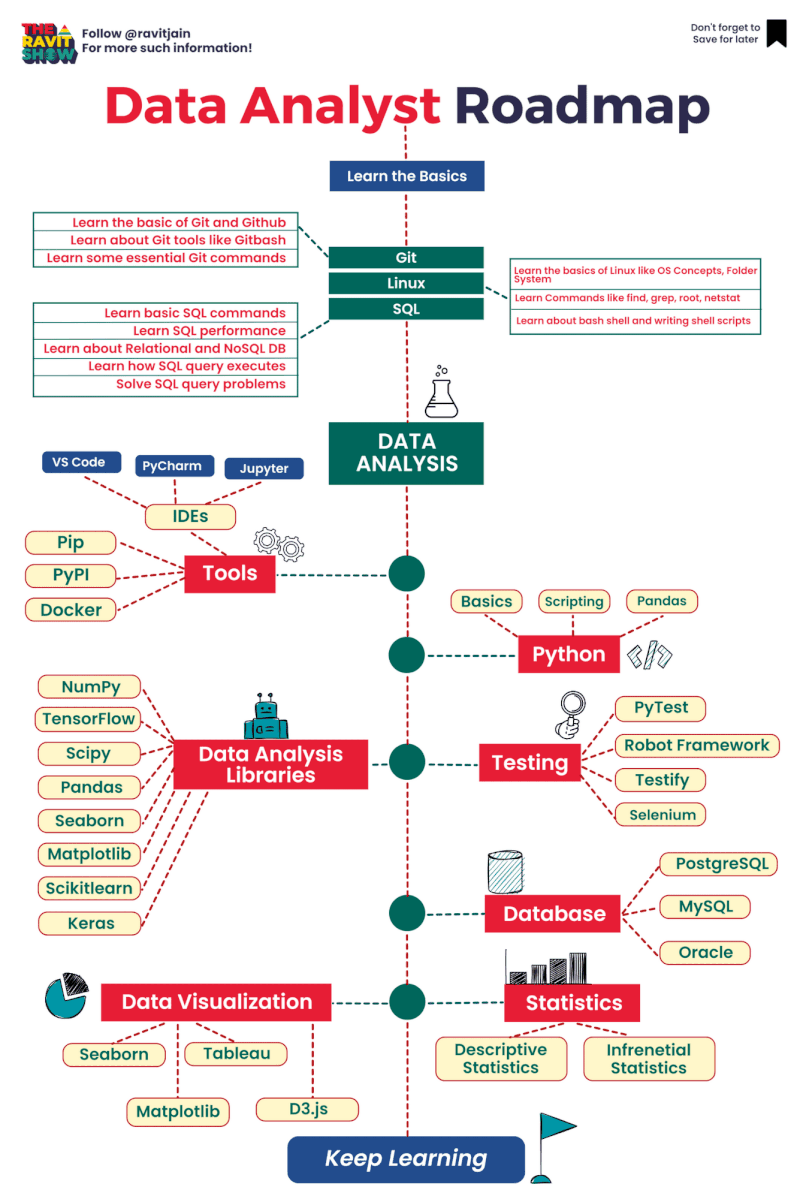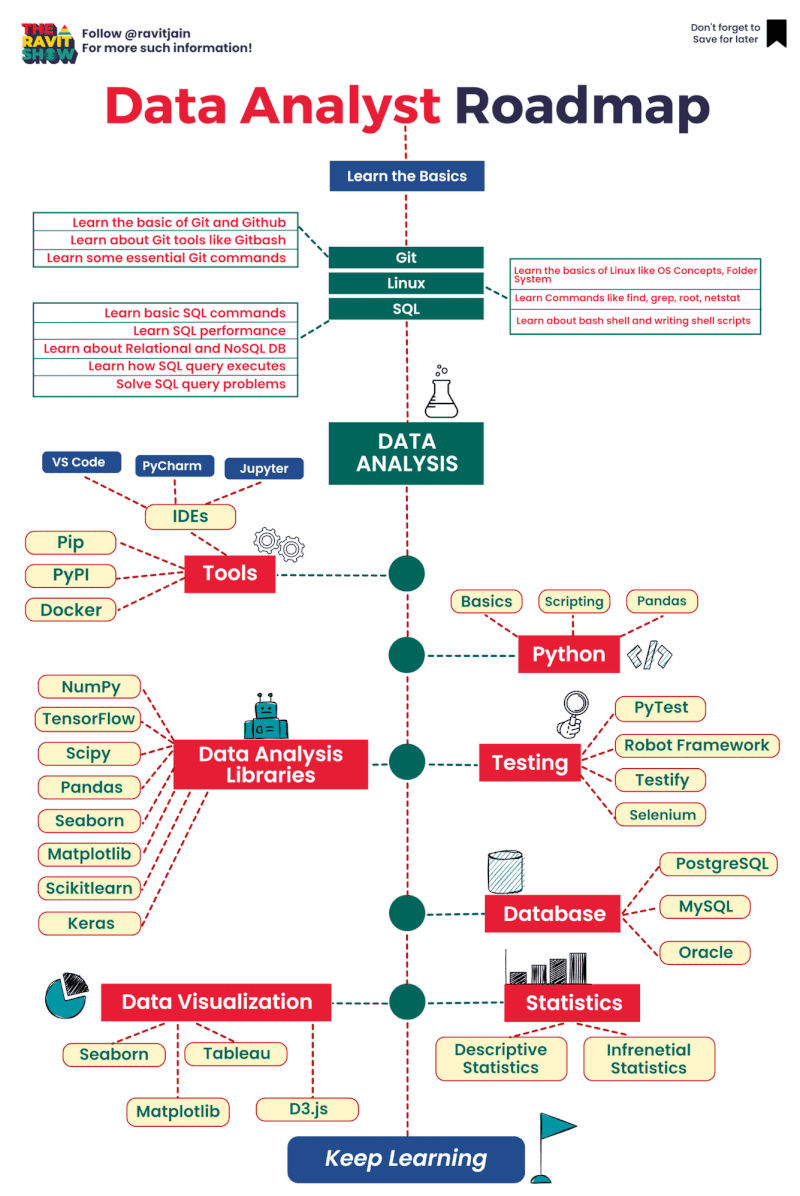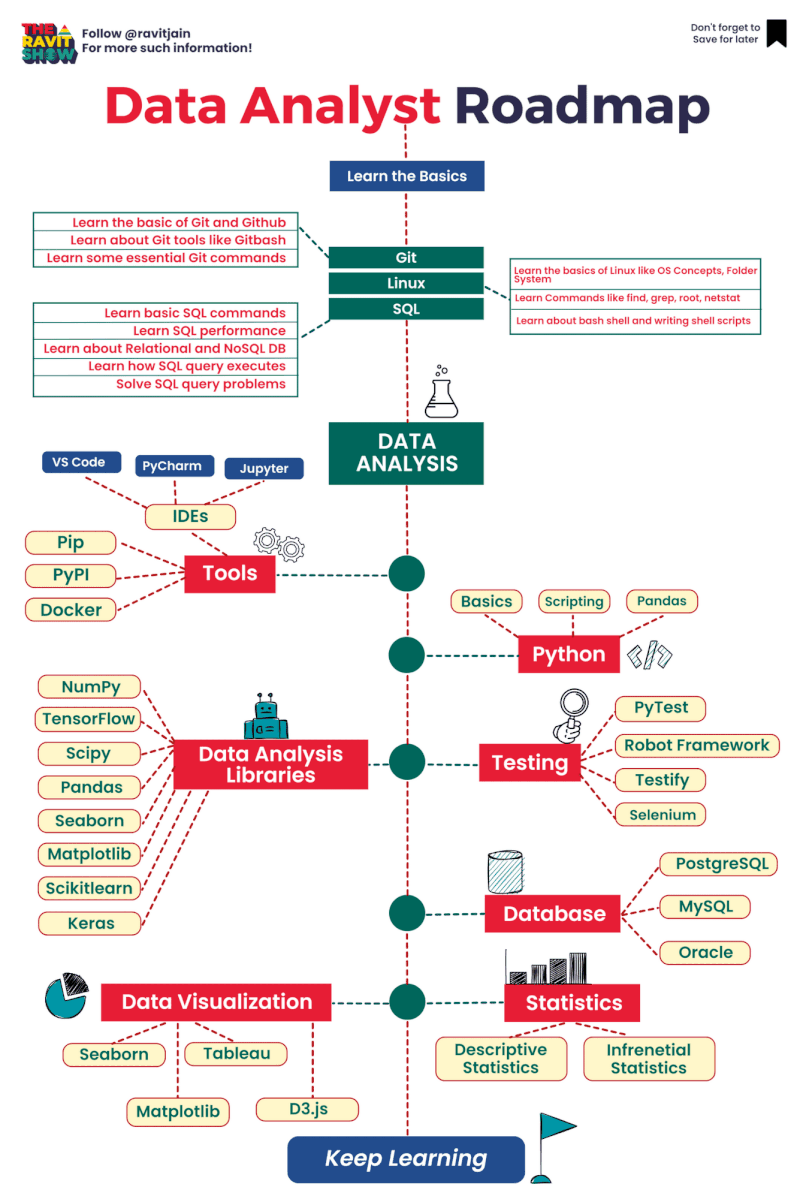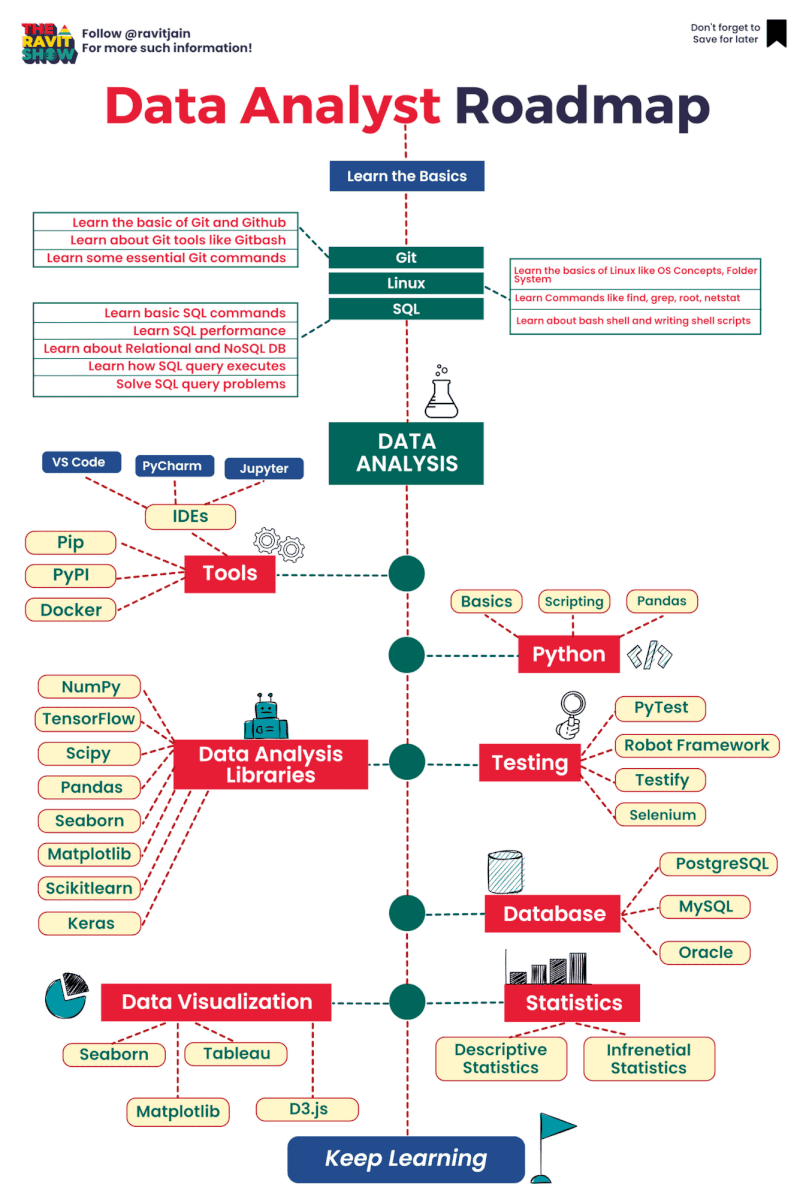
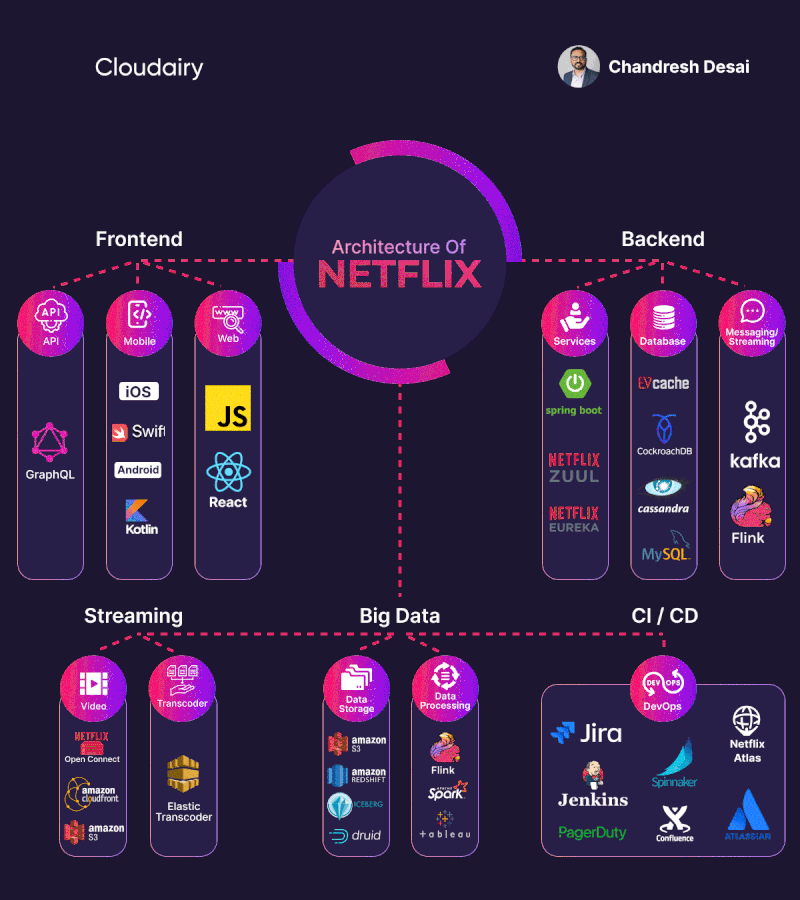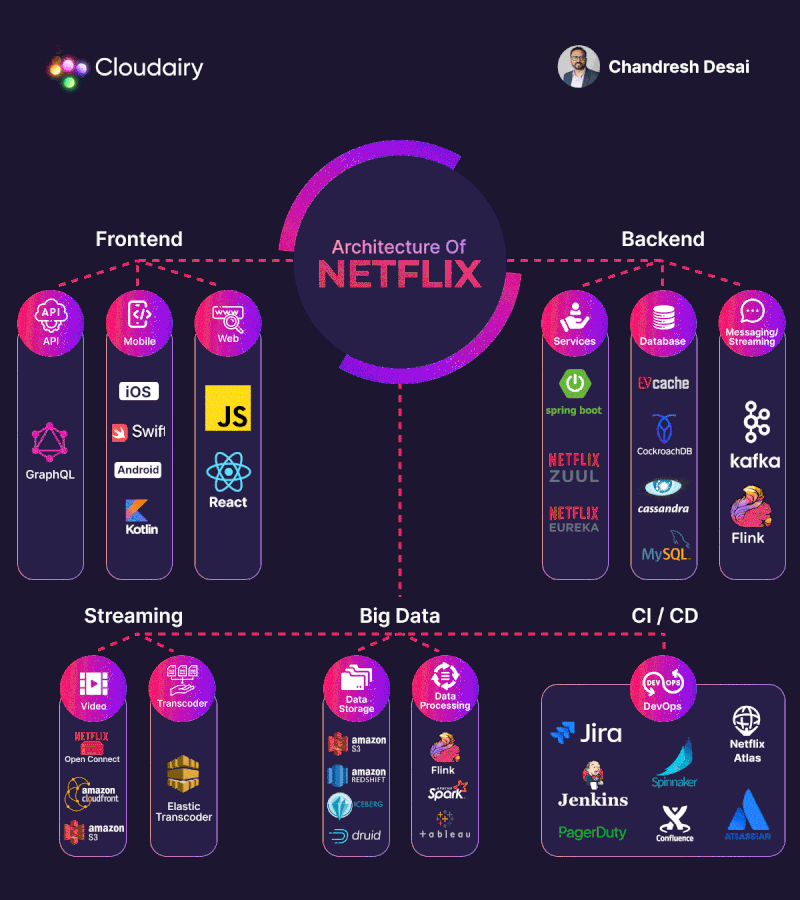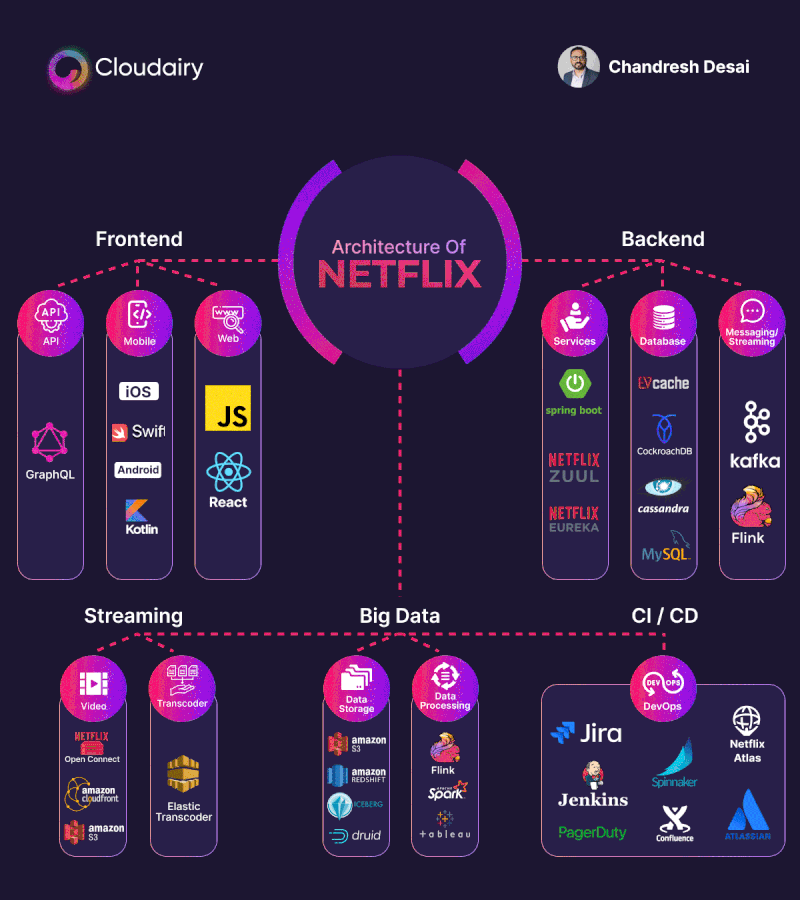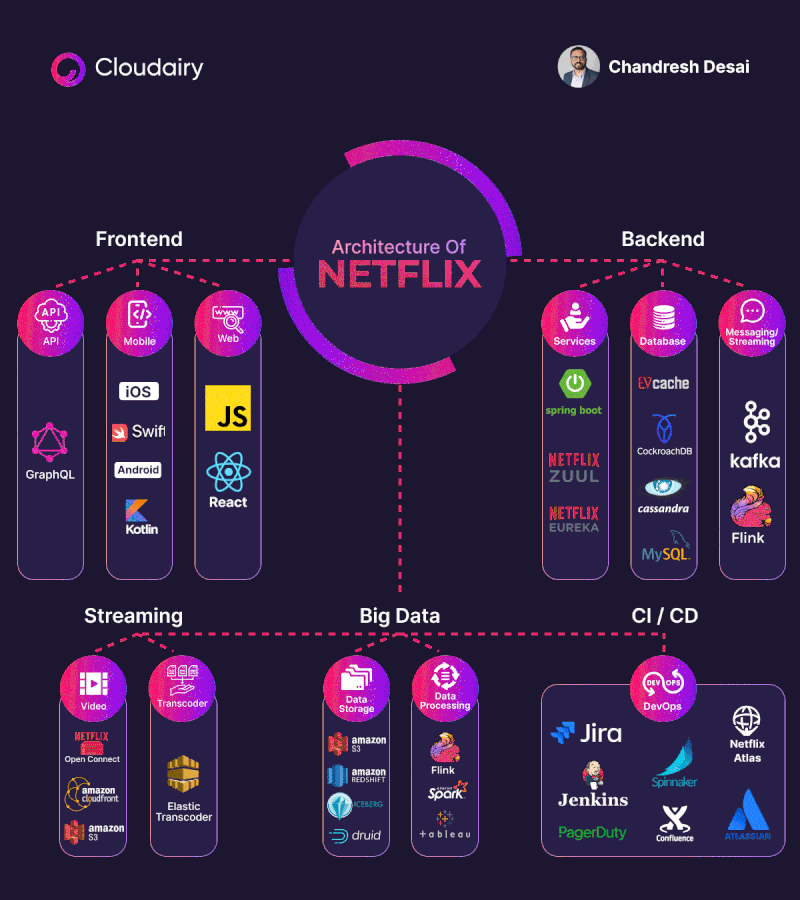
Cần confirm những gì khi nhận được điều tra nguyên nhân EC2 instance fail?
Share Everywhere







Lưu ý quan trọng trước khi bắt đầu bài viết:
Bài viết này có 2 assumption như sau:
– Dùng Linux
– Có thể access AWS console để confirm một số mục
1. Instance status check
Kiểm tra CloudWatch status check metrics:
Có 2 loại status check: system status và instance status -> Với mỗi loại sẽ có cách xử lý vấn đề khác nhau, nên phải biết rõ là đang fail cái gì
– Check cái gì?
- CloudWatch metrics
- System status (StatusCheckFailed_System)
- Instance status (StatusCheckFailed_Instance)
– Confirm cái gì?
- Nếu system status check fails, thì có thể đã có lỗi xảy ra ở hardware host cái instance đó
- Nếu instance status check fail, thì có thể do OS hoặc network setting của EC2 instance.
=> Cách để trouble shoot instance status check thì có thể tham khảo tài liệu của AWS:
Instance Status Check
>>> https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/monitoring-system-instance-status-check.html
2. Confirm metrics:
Ngoài check 2 metrics quan trọng trên, nên check thêm 2 metrics sau (dù từ 2 metrics trên đã tìm ra lỗi cũng nên check tiếp để tránh bỏ sót nguyên nhân):
- CloudWatch metrics
- CPU Utilization
- CPU Credit (CPUCreditBalance)
- NetworkIn / NetworkOut
- Số lượng disk IOs (DiskReadOps / DiskWriteOps)
- CloudWatch Custom Metrics
- Available memory (mem_free)
- Free disk space (disk_free)
- Số lượng process startups (pid_count)
– Confirm cái gì?
Confirm gì thì có phần hơi case-by-case. Tuy nhiên, hint là hãy thử kiểm tra xem có điều gì đột ngột tăng cao bất thường ở đây hay không? Nếu xem ở metrics, thì hãy chịu khó narrow-down time range chút để có thể nhìn rõ hơn những điểm spike.
Có rất nhiều metrics, nhưng làm sao để đọc data? -> Có lẽ không còn cách khác ngoài kinh nghiệm, vì tương quan metrics này với metrics kia đôi khi cho ra kết quả có ý nghĩa khác nhau. Tuy nhiên, hint là hãy cố gắng nắm rõ ý nghĩa từng metrics là gì. Nếu vượt threshold thì điều gì xảy ra?
3. Kiểm tra CloudTrail:
Check CloudTrail sẽ cung cấp khá nhiều thông tin hữu ích bao gồm AWS Management Console, AWS CLI và các actions thực thi bởi SDK hay APIs. Đôi khi bạn không kết nối được chưa chắc đã là do instance fail đâu, mà lại có hành động stop hay restart ở đây.
4. Kiểm tra log file
Kiểm tra logs ở các Log groups, hay các logs được lưu S3: Hãy kiểm tra các logs trước thời điểm xảy ra lỗi khoảng 30 phút – 1 tiếng, trong thời điểm xảy ra lỗi, và cả sau thời điểm xảy ra lỗi ít nhất 30 phút để xem tình trạng có còn tiếp tục, hay có gì bất thường mới xảy ra không?
5. Kiểm tra log của app (nếu đã được streams lên CloudWatch hay tools thì check ở CW hoặc các tools này, nếu không thì phải nhảy vào server để check)
Đôi khi fail là do app. Nhưng nếu log app không được stream, chỉ nằm ở trong instance hoặc streams lên các tools mà bạn không được access thì đành chịu, nhưng nếu làm thực tế thì đừng quên chúng ta còn cần phải confirm cả log của app!